Technical Documentation
Table of Content
Concept
Collada respectively .dae is a file format which represents 3D vector graphics into a XML format. Beyond this base mission it stores many add data that may be used by GL renderers such as shadings normals lamps and much more that affects the base model too. According to this collada specification is a script of almost 400 pages and the varieties of combinations is very huge.
A former version of this software was based on the concept: Each xml tag gets a java class and then we extract what we need from them to Processing. That was a bad idea: Too less flexible.
The actual concept is better:
The benefit appears instantly:
Overview
The most interesting part is located into "coreproc" package. We focus to the classes "SaxParser" "ObjectLinker" "DataAssembler" and "LinkingSchema_*.xml". As in XML defined, the software does following 3 steps:
All 3 classes and all tools in asmbeans send debug informations to the Log class. More details can be found in javadoc code comments or linking schema specifications.
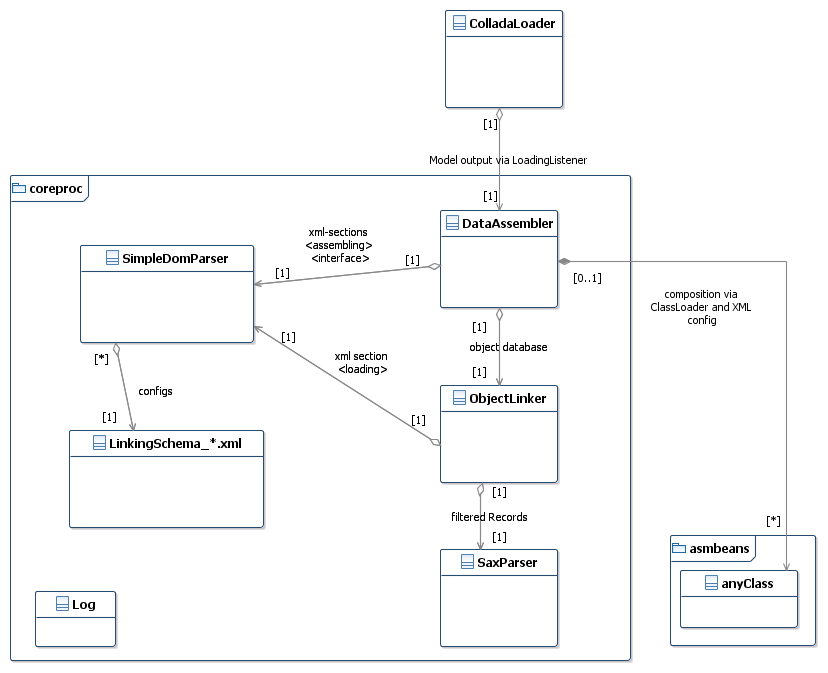
Step 1: SaxParser
SaxParser is that class what read .dae file from begin to the end. It compares the collada XML stream to a search pattern (got from ObjectLinker). A pattern matches if XML depth and XML tag name of stream is arrived. In this case a "SaxParser.Record" object is created for this tag. It can either
SaxParser process more than one patterns as "OR" and nested patterns as "AND". Nested patterns implicate children, top levels parents.
Mostly SaxParser scans collada file several times, depending on the num of <entities> tags in linking schema (see also linking schema specifications).
Step 2: ObjectLinker
ObjectLinker creates and holds an object oriented database. So we get an abstraction to collada XML structure. ObjectLinker get its instructions via <loading> section in linking schema.
In natural order and for each <entities> tag a new scan via SaxParser starts again committing search patterns. Each returned "SaxParser.Record" objects is stored then into tables and linked/backlinked to other Records (see also linking schema specifications).
A "SaxParser.Record" object contains:
Step 3: DataAssembler
DataAssembler combines the data from database into final wrapper objects they can be drawn by Processing. To do that it iterates through the database tables and invokes functions via system class loader. The <assembling> section from linking schema defines iterations and function calls.
The functions themselves are located in package "asmbeans". They do atomic defined tasks and may be either proprietary or common compatible to different linking schemas.
A next important part is the IO stub. The end results from the whole procedure must be returned to user on the other hand there may be some options coming from user what some functions need.
The input is realized via user options. (Read the user manual part). The output goes via callbacks (see also <interface>). The ColladaLoader class creates on startup an empty listener and commit it here.
XML Specifications
In General
Any XML config files is always located inside package "jar://ch.dieseite.colladaloader.coreproc". The xml's is the tree trunk for the whole behavior of colladaLoader software. Its file names underlies a naming convention:
For example: If user defines:
Properties.put("LinkingSchema","Sketchup");
then "LinkingSchema_Sketchup.xml" is opened + executed.
If anyone want to create a new xml so please check it with this linkingSchema.xsd schema definition. As next it follows details for each tags.
XML Schema
| <loading> | |
|---|---|
| Description: | Section is read by ObjectLinker. The order of child tags matters how to build up database tables |
| Attributes: | no |
| Occurence: | exactly 1 |
| Parent: | root |
| Child: | entities |
| <assembling> | |
|---|---|
| Description: | Section is read by DataAssembler. The order of child tags matters how to combine database content into Processing handable objects. |
| Attributes: | no |
| Occurence: | exactly 1 |
| Parent: | root |
| Children: | iteration, function |
| <interface> | ||
|---|---|---|
| Description: | I/O stub definition between Processing
user sketch and DataAssembler respectively its static Methods
into "asmbeans" package. The interface class is
loaded via java class loader and must have a constructor
AnyName(java.utils.Properties input, DataAssembler.LoadingListener output)If a function needs options then Properties is read. If a function wants to add final Triangles or Lines to ColladaModel then LoadingListener methods is fired. |
|
| Attributes: | name | Defines a variable/descriptor name inside xml. It can be added via <paramlist> tag to any function. Required! |
| class | fully qualified class name, should be located in "asmbeans" package. Required! | |
| Occurence: | exactly 1 | |
| Parent: | root | |
| Children: | no | |
| <function> | ||
|---|---|---|
| Description: | Defines static Methods
into "asmbeans" package. They should do atomic defined tasks and
must have a signature like:
public static AnyTypeOrVoid anySmartDefinedName(ArrayList<DataAssembler.Param> p) |
|
| Attributes: | name | Definition of method name. Required! |
| class | fully qualified class name the method belongs to, should be located in "asmbeans" package. Required! | |
| result | descriptor, defines the returned object from that method (if not void) and can be assigned to other functions via paramlist. Optional | |
| Occurence: | zero or more | |
| Parents: | assembling or iteration | |
| Child: | paramlist | |
| <paramlist> | ||
|---|---|---|
| Description: | Definition for method params in functions. Any descriptor/variable is allowed. If params is required depends on the function implementation | |
| Attributes: | source | Descriptor name. Required! |
| args | A simple additional string, implementation depending. Optional | |
| Occurence: | zero or more | |
| Parent: | function | |
| Child: | no | |
| <iteration> | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Description: | Describes an instruction to DataAssembler
to iterate a collection of objects. There exist 4 supported types they
can be iterated:
|
|||||||||||
| Attributes: | source | Descriptor name for a collection. Required! | ||||||||||
| tuple | Descriptor name for a current tuple from collection. Required! | |||||||||||
| Occurence: | zero or more | |||||||||||
| Parent: | assembling or iteration | |||||||||||
| Child: | function or iteration | |||||||||||
| <entities> | ||
|---|---|---|
| Description: | Initiate ObjectLinker to add
Records returned from SaxParser into a new or existing database table.
Each occurred entities tag starts (in natural order) a new separate scan
through collada file and processes search patterns of
<target> instructions. The table is realized
as a java.util.TreeMap. The database packs tables into a java.util.HashMap
so we have as result:
HashMap<poolname,TreeMap<uniqueID,recordObject>> respectively HashMap<String,TreeMap<String,SaxParser.Record>> |
|
| Attributes: | poolname | Name resp. decriptor of database table. Required! |
| Occurence: | one or more | |
| Parent: | loading | |
| Child: | target | |
| <target> | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Description: |
This tag gives instructions which data from collada xml stream shall
be picked up and be stored into database. It also contains tuple linking
definitions. (primary + foreign keys). <target> may contain nested tags. If so there exist restrictions about attribute occurrences: If <target> has nested tags and all patterns match then each resulting SaxParser.Record have child Records likewise |
|||||||||||
| Attributes: | pattern | A required search pattern for collada xml stream.
A pattern can either match by tag name (Syntax: "tagName")
or tag name and attribute value (Syntax: "tagName#attribName=value").
Each xml depth is separated by "/". For Example: (see also SaxParser)
|
||||||||||
| idValueIn | Table Unique ID, optional. The ID value for
database can be assigned in 3 ways:
Applied in all 3 cases: any "#" tabstops or spaces from resulting values won't be stored to DB. |
|||||||||||
| nextIdValueIn | Foreign key to another Record, optional. Same syntax rules as "idValueIn" is applied. | |||||||||||
| nextEntity | Foreign table name, optional | |||||||||||
| Occurence: | one or more | |||||||||||
| Parent: | entities or target | |||||||||||
| Child: | target | |||||||||||
Appendix: collada <geometry>
To get an intro into philosophy of collada we take a view to geometry tag. Most of child tags is not used for our purpose. And ,not really surprising, Sketchup takes another way than Blender. We focus to the "Sketchup way".
If we say "triangulate" a 3D model that means any form can be splitted into single triangles in a 3D space (x,y,z positions). In addition, grid structures can be displayed as triangulated lines. So a <geometry> tag links this data via subtags <lines> and <triangles>.
Next picture is an example for one textured triangle. For texture and vertice positions exist separate <float_array> tags (subtags of <geometry>) they contain raw coords here. The meanings for each values is showed in picture below.
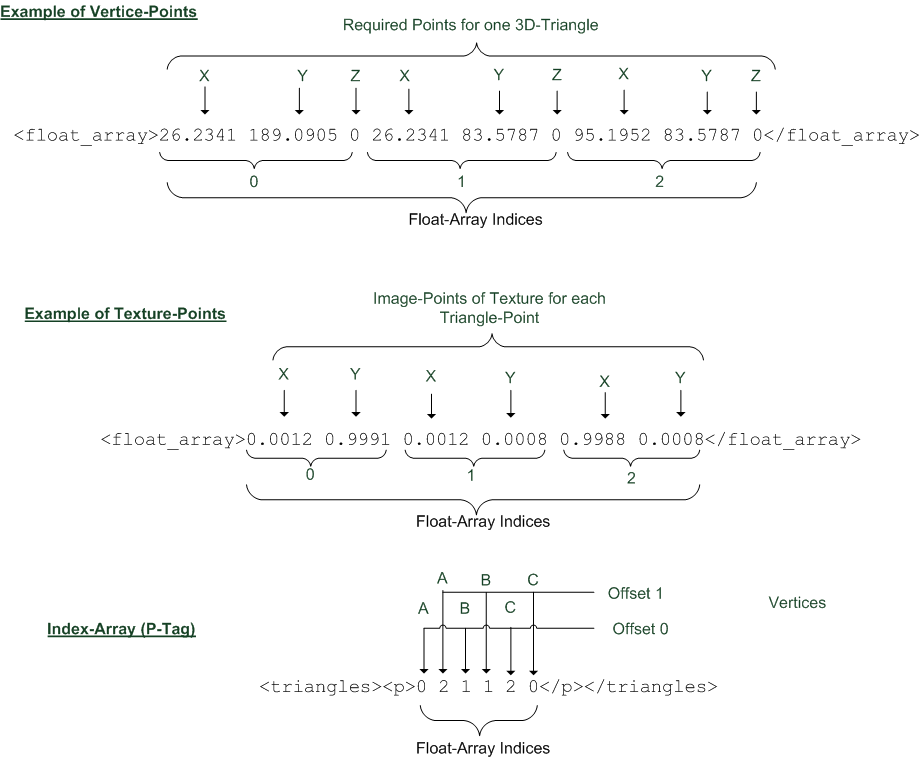 Zoom
Zoom
To get raw data access another tag is needed: The <p> contains array indices to find coords in <float_array>. To do it more complicated, indices for texture and vertices is multiplexed into the same tag. To demux it the attribute "offset" of <input> is read by application. See picture again.
In this example the offset 1 is allocated to textures and the vertices have offset 0. After parsing we get following results:
| Vertice: | |||
| Point A: | x=26.2341 | y=189.0905 | z=0.0 |
| Point B: | x=26.2341 | y=83.5787 | z=0.0 |
| Point C: | x=95.1952 | y=83.5787 | z=0.0 |
| Textures for: | |||
| Point A: | x=0.9988 | y=0.0008 | |
| Point B: | x=0.0012 | y=0.0008 | |
| Point C: | x=0.0012 | y=0.9991 |
